

人工智能刚刚迎来了自己的“斯普特尼克时刻”。
上周,中国大型语言模型(LLM)初创公司 DeepSeek 在低调运营后正式亮相,令美国市场大感意外。
DeepSeek 比 ChatGPT 等其他 LLM 更快、更智能、资源占用更少。无论是内容创作还是基础查询,它的速度都远超前代模型。更重要的是,该模型具备“自主思考”能力,因此据称其训练成本比之前的模型更低。
听起来很棒,对吧?但如果你是一家押注于美国 AI 产业的科技公司,那就不一定了。市场在周一对这一进展作出了剧烈反应。科技股集体暴跌,市值蒸发超过 1 万亿美元——相当于比特币市值的一半。其中,英伟达(Nvidia)股价单日重挫 17%,市值损失 5890 亿美元,创下美国股市历史上最大单日市值损失纪录。英伟达及其他科技股的下跌拖累纳斯达克综合指数当日下跌 3.1%。
且市场的抛售并未局限于科技股。能源股同样遭受重创,自然气、核能和可再生能源企业 Vistacorp(在德克萨斯州有大规模业务)股价暴跌约 30%,而正在重启三里岛核电站以为微软数据中心供能的 Constellation Energy 股价也下跌超过 20%。
市场对 DeepSeek 的担忧很简单:LLM 计算效率的提升速度远超预期,其直接后果是市场对 GPU、数据中心及能源的需求减少。而巧合的是,这一模型爆红的时间点正好与前总统特朗普宣布 5000 亿美元的“星门计划”(Project Stargate)相隔数日,该计划旨在加速美国 AI 基础设施建设。
对于 DeepSeek 的影响,专家们的看法不一。一方面,有人认为这可能是 AI 行业的重大利好,而非灾难——就像内燃机效率的提升并未减少汽车需求,反而推动了行业增长。
另一方面,社交媒体上流传的关于 DeepSeek 训练成本的数据可能具有误导性。尽管新模型确实降低了成本,但远没有传言中的那么夸张。
认识 DeepSeek
DeepSeek 由中国工程师梁文峰(Liang Wenfeng)于 2023 年 5 月创立,并获得对冲基金 High-Flyer 的投资,该基金也是梁文峰在 2016 年创办的公司。DeepSeek 于 1 月 20 日开源了首个模型 DeepSeek-R1,并在上周末迅速走红网络。
DeepSeek-R1 具备多项独特功能,使其与其他模型区别开来,包括:
- 语义理解:DeepSeek 具备“读懂弦外之音”的能力。它采用“语义嵌入”(semantic embeddings)技术,可以推测查询背后的意图和更深层的语境,从而提供更细致入微的回答。
- 跨模态搜索:它能够解析并交叉分析不同类型的媒体内容,意味着可以同时处理文本、图片、视频、音频等多种数据。
- 自动适应:DeepSeek 具备持续学习和自我训练的能力——输入的数据越多,它的适应性就越强。这可能使其在不需要频繁重新训练的情况下依然保持可靠性。换句话说,我们可能不再需要像以往那样定期输入新数据,因为模型可以在运行过程中自主学习和调整。
- 海量数据处理:据称,DeepSeek 可处理 PB 级(Petabyte)数据,使其能够应对其他 LLM 可能难以处理的庞大数据集。
- 更少的参数:DeepSeek-R1 总参数量为 671 亿,但每次推理仅需 370 亿个参数,而 ChatGPT 每次推理所需的参数量估计在 5000 亿到 1 万亿之间(OpenAI 并未公开具体数字)。参数是指模型在训练过程中用于引导和优化学习的输入及组件。
除了上述特点外,DeepSeek 最吸引人的地方在于其自我调整和自主学习的能力。这一特性不仅节省时间和资源,还为 AI 代理的发展奠定了基础,使其能够应用于机器人、自主驾驶、物流等领域的自治 AI 系统。
Pastel 创始人兼 CEO Jeffrey Emmanuel 在其文章《做空英伟达的理由》(The Short Case for Nvidia Stock)中对此突破做出了精彩总结:
“通过 R1,DeepSeek 基本上攻克了 AI 领域的一座‘圣杯’:让模型在没有大规模监督数据集的情况下实现逐步推理。他们的 DeepSeek-R1-Zero 实验展示了一项惊人的成就:通过纯强化学习和精心设计的奖励函数,他们成功使模型完全自主地发展出复杂的推理能力。这不仅仅是解决问题——模型能够自然地生成长链推理过程,自我验证其工作,并在处理更困难的问题时分配更多计算资源。”
DeepSeek 让华尔街恐慌的真正原因
DeepSeek 确实是 ChatGPT 的增强版,但这并不是上周让金融界震惊的真正原因——真正让投资者恐慌的是该模型的训练成本。
DeepSeek 团队自称,该模型的训练成本仅为560 万美元,但这一数据的可信度存疑。
从 GPU 小时(即每块 GPU 每小时运行的计算成本)来看,DeepSeek 团队声称,他们使用了 2,048 块英伟达 H800 GPU,总计 278.8 万 GPU 小时,完成了预训练、上下文扩展及后训练,计算成本约 2 美元 /GPU 小时。
相比之下,OpenAI CEO 山姆·奥特曼(Sam Altman)表示,GPT-4 的训练成本超过 1 亿美元。GPT-4 的训练周期为 90 至 100 天,使用了 25,000 块英伟达 A100 GPU,总计 5,400 万至 6,000 万 GPU 小时,每小时计算成本约 2.50 至 3.50 美元 /GPU 小时。
因此,DeepSeek 训练成本的“标价”与 OpenAI 相比,直接引发了市场的恐慌性抛售。投资者纷纷自问:如果 DeepSeek 能以 OpenAI 训练成本的一小部分打造出更强大的 LLM,那么我们为何还要在美国斥资数十亿美元建设 AI 计算基础设施?这些所谓的“必要”算力投资,真的有意义吗?AI/HPC 数据中心的投资回报率(ROI)和盈利模式又将何去何从?
下方的图表直观展示了训练 DeepSeek 与 ChatGPT 所需的数据中心每 GW 收入情况,进一步突出了这一问题。
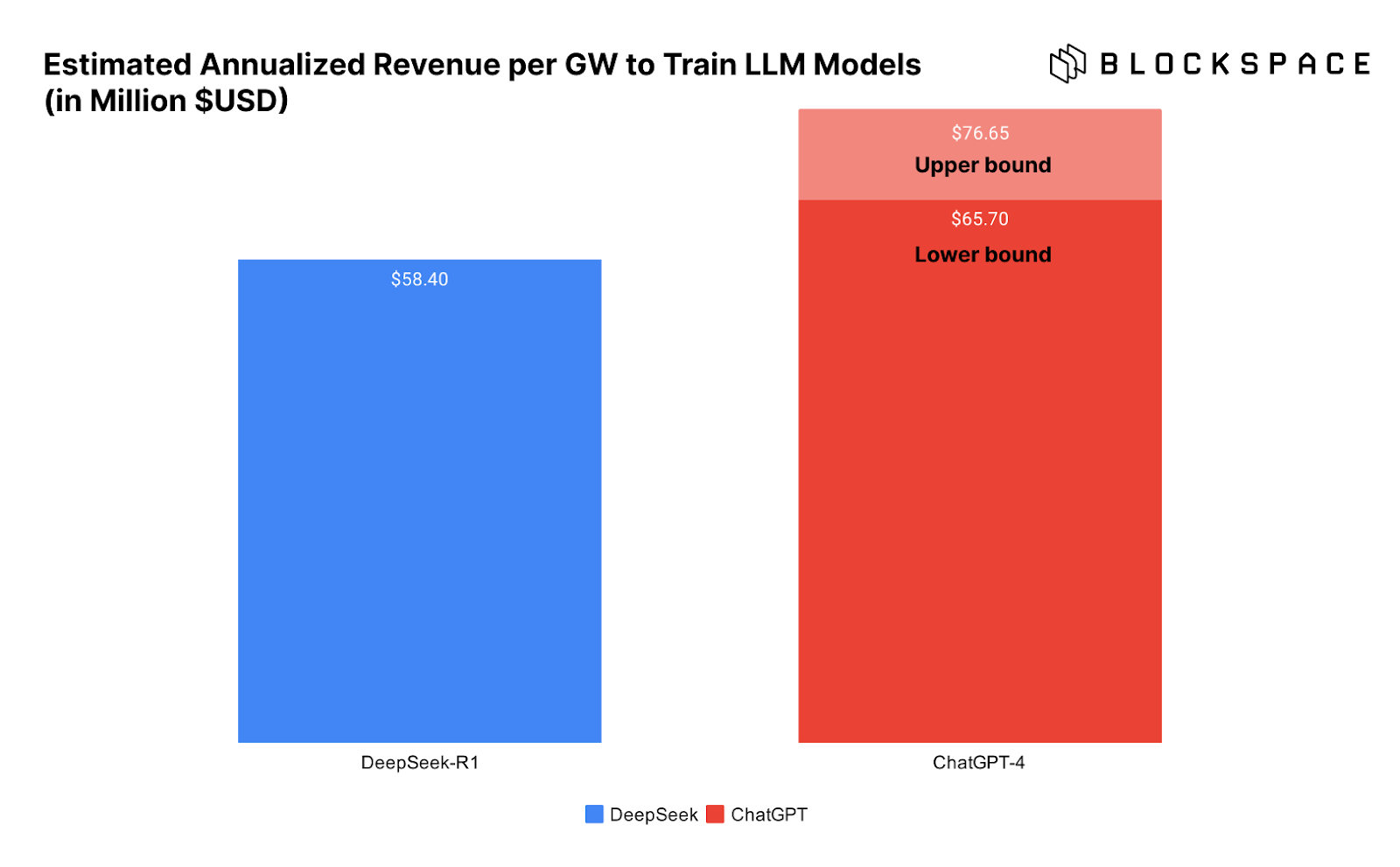
问题在于,我们并不能确定 DeepSeek 真的以如此低的成本完成了模型训练。
DeepSeek 训练成本真的如此之低吗?
然而,DeepSeek 真的只花了 560 万美元训练模型吗?不少业内人士对此表示怀疑,而且理由充分。
首先,在 DeepSeek 的技术白皮书中,团队明确表示,“所述训练成本仅涵盖 DeepSeek-V3 的正式训练,不包括此前在模型架构、算法或数据上的研究和消融实验成本。”换句话说,560 万美元只是最终的训练成本,而在模型优化过程中,还有更多资金投入。
因此,Atreides Management 首席投资官(CIO)加文·贝克(Gavin Baker)直言,“560 万美元的成本数据极具误导性。”
“换句话说,如果一个实验室已经在前期研究上投入了数亿美元,并且拥有更大规模的计算集群,那么确实可以用 560 万美元完成最终训练。但 DeepSeek 显然不止使用了 2,048 块 H800 GPU——他们早期的一篇论文就提到了一个由 10,000 块 A100 组成的集群。因此,一个同样优秀的团队如果想要从零开始,仅凭 2,000 块 GPU 训练出类似 R1 的模型,根本不可能只花 560 万美元。”
此外,贝克指出,DeepSeek 采用了一种名为“知识蒸馏”(distillation)的方法,从 ChatGPT 汲取经验来训练自己的模型。
“DeepSeek 很可能无法在没有 GPT-4o 和 GPT-4o1 完全开放访问的情况下完成训练。”
DeepSeek、能源消耗与杰文斯悖论
尽管 DeepSeek 训练成本仅为 560 万美元的说法存疑,但加文·贝克(Gavin Baker)指出,该模型的多项突破——如自学习、参数更少等——确实使其训练和推理(即 AI 运行成本,行业术语称之为“推理”)变得更加低廉。
贝克声称,使用 DeepSeek-R1 的成本比 ChatGPT 的 o1 版本低 93%,每次 API 调用的费用大幅下降。尽管 93% 这一具体数字是否准确仍有争议,但关键在于,DeepSeek 的推理成本更低,甚至可以在 Mac Studio Pro 等本地硬件上运行。
这才是 DeepSeek 的真正突破——AI 变得更加经济可用。正如一位匿名评论者所说,这感觉就像微软开源了互联网浏览器,从而彻底摧毁了 Netscape 的付费访问模式。
DeepSeek 彻底打开了 AI 的新模式,使 AI 发展进入了一个全新的竞争阶段——“现在的竞争重点已经从 AI 训练转向 AI 推理”,借用 Chamath Palihapitiya 的话来说。
AI 驱动的数据中心与电力行业热潮何去何从?
正如我们在文章前面所提到的,更高效的发动机是否减少了汽油需求,或者对依赖汽车的行业造成了负面影响?
杰文斯悖论(Jevons Paradox)认为,当技术进步提升了资源利用效率时,资源本身的需求反而会上升,因为更低的成本会促使更广泛的应用。比特币矿工对此深有体会——尽管 ASIC 矿机的能效逐年提升,但比特币网络的算力仍然持续增长。
从目前来看,市场迎来了一个更强大的竞争者,但游戏规则并未改变。如果 AI 推理和训练成本下降(而这本就是必然趋势),那么它将解锁更多应用场景,并进一步推动 AI 产业需求增长。
